
 Locations
Locations
Photo credit:https://bit.ly/3qPPuND
The World Health Organisation (WHO) coined the word "infodemic” referring to an overabundance of information and the rapid spread of misleading or fabricated news, images, and videos. It furthermore added that - Like the virus, it is highly contagious and grows exponentially. It also complicates COVID-19 pandemic response efforts.
“We’re not just battling the virus,” said WHO Director-General Tedros Adhanom Ghebreyesus. “We’re also battling the trolls and conspiracy theorists that push misinformation and undermine the outbreak response.”
Responding to this, the Accelerator Lab in Tanzania together with its partner Xsense AI designed an experiment to conduct web scrapping on Twitter data to understand the extent of misleading information related to COVID-19 in Tanzania, this exercise was conducted right after the first patient was identified in the country. The exercise intended to develop data sets that authorities can use to develop communication messages related to the pandemic. We used Kinondoni district in Dar Es Salaam region as a pilot.
We extracted data produced in four consecutive days, resulting to 20,422 related tweets. 10,000 tweets were used to train our deep learning model. We used popular model for Natural Language Pre-processing (NLP), the Long Short-Term Memory (LSTM). The tweets were labelled as either COVID or NON-COVID. To account for misinformation, the dataset was further labelled as INFORMED and MISINFORMED on tweets related to COVID. By using the trained deep learning model, we were able to automatically classify the remaining 10,422 data into the four categories, namely COVID, NON- COVID, INFORMED, and MISINFORMED.

Official Twitter account of the United Nations Secretary General
On the overall analysis of the pulled tweets, the top 20 most discussed topics on twitter. Figure 2F shows COVID-19 related words were the most dominating words on twitter within the Kinondoni district. In both of our pulled tweets from 21st to 24th April, was dominated with the word “GOD”, as it can be seen in Figure 2, A-E. Also, figure 2, E which plotted the overall discussed topics on Twitter, still the name "GOD", dominated the tweets posted and retweeted.
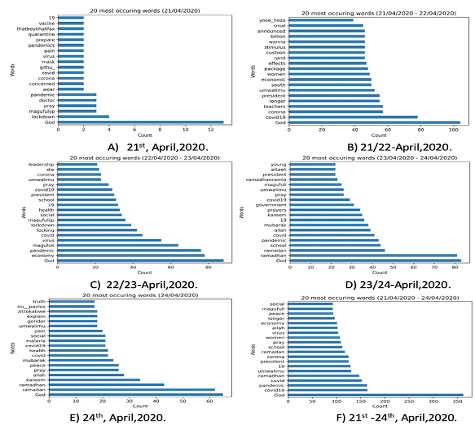
Figure 2: The top 20 most common spoken words on twitter, 21st-24th April 2020.
Figure 3 below shows the trend of COVID-19 related tweets against other tweets in four days, April 21st -24th, 2020. Although people continued to tweet about other issues, COVID related tweets contributed an average of 11.8% to the discussed topics. The number of retweets and likes COVID related tweets received further tell the extent to how much COVID related posts occupied online conversations.
In our analysis of tweets originating within Kinondoni district, we found that more than 18% were discussing COVID-19 as shown in figure 3 A.
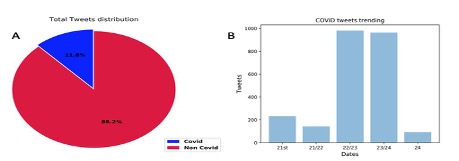
Figure 3 A: Four days tweets distribution, B: Four days trending of tweet related to COVID-19, in Kinondoni district
Although information on prevention and care was provided through other channels, we tried to find out how informed this community was based on incoming tweets. In this regard, we checked how well people were informed about CORONAVIRUS/COVID-19 by performing sentiment analysis on the posted tweets. We found a relatively higher percentage (12.4%) of all tweets related to COVID seemed not informed about the pandemic out of all 2413 COVID related tweets we pulled based on WHO guidance.
Conclusion
Our ability to create an Artificial Intelligence algorithm that can perform sentiment analysis of the data has set a proof that we can automate the process on how the analysis of social media data can be done. The detection of most trending topics, shows that social media data analysis can be used as an early detection tool for situations like epidemics and disasters for early intervention. Although social media data pose a risk of being a major source information, our ability to detect this can be used in taking countermeasures in combating the problem of misinformation. At the time of writing the country office was planning to support the government of Zanzibar through Zanzibar Commission for Tourism to conduct web scrapping on popular tourists websites to understand the problem of lower rate of returning tourists after first visit to the islands.
Note: This analysis was based only on the English tweets. This is because of absence of Swahili digital libraries Artificial Intelligence and Machine learning applications. This blog argues for the need of collection of machine learning ready Swahili dataset, to be able to include swahili in digital platforms.
Missed our previous blog? Please click here.
For more inforamtion about UNDP accelerator programme visit: https://acceleratorlabs.undp.org/
Special thanks to: Dr. Deogratias Mzurikwao, Director and Researcher at Xsense AI, Tanzania
By Peter Nyanda, team Lead and Head of Exploration, UNDP Accelerator Lab Tanzania




