
 Locations
Locations
Zanzibar's Indian Ocean Coastline ©Getty Images
This blog post serves as an introduction to a web-scraping project whose design was inspired by the UNDP Tanzania Accelerator Lab's deep learning work in partnership with Xsense AI. In our previous blog, we discussed how we used Twitter data to train some deep learning models to effectively evaluate the extent of online misinformation on the COVID19 pandemic. In this experiment we will use web scraping techniques to extract, apply data analytics method to clean, annotate, analyze, interpret, and visualize data from popular tourists’ websites to gather feedback by visitors coming to the islands of Unguja and Pemba in Zanzibar. We will finally train a deep learning model with the cleaned data for automatic analysis.
The Problem
Zanzibar is endowed with cultural, historic, natural, and man-made tourism features that have the potential to transform it into an up-market and competitive tourist destination in the Indian Ocean archipelagoes. It is the main industry that connects all other economic sectors. The tourism industry in Zanzibar accounts for approximately 27 percent of GDP and generates more than $400 million in revenue. COVID-19 has arisen several economic, social, and environmental challenges that are hindering private investment and the ease of doing business in Zanzibar's tourism sector. The key challenges include under capacitated institutions in the sector, lack of professional competence and crumbling infrastructures, to name a few. However, for the purposes of this experiment, we have focused our efforts on determining the problem of lower returning rate of tourists after first visit to the islands.
The 2017 International Visitor Exit Study showed that the majority of the top 15 Zanzibar source markets with the exception of Kenya were first time visitors to the islands, with repeat visitors accounting for just around 14 percent of the total, as indicated in the chart below:
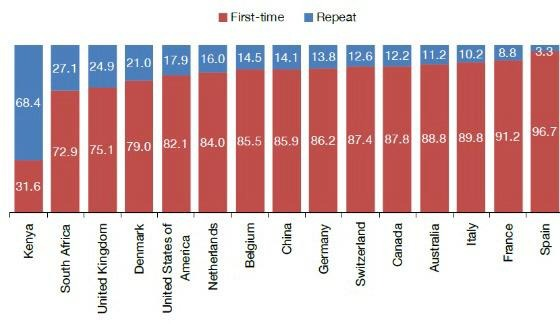
First time and repeat visitors by Top 125 source markets, Zanzibar ©NBS, 20217
We plan to collect data on a variety of tourism-related topics, including hotel listings, location data, aviation data, and review and feedback data, to name a few. Scraping visitor opinions and reviews from social media, customer portals, online communities, and forums.
About web scrapping
Data scraping, also known as web scraping, is the process of gathering information from the internet in an efficient manner. It does not entail repetitive typing or copy-pasting. Web scraping tools work by searching for the required data, compiling it, and storing it on a computer. Web scraping, as opposed to screen scraping, which only copies pixels displayed onscreen, extracts underlying HTML code and, with it, data is stored in a database. After that, the scraper can replicate the entire website's content elsewhere.
You may wonder, why data scraping? the truth is that a tourist’s travel decision is influenced by a variety of complex factors. Social media and travel review websites are the most important of these, so let us dissect this new online travel industry. On the one hand, there are travel e-commerce websites that sell travel products like hotels, flights, and car rentals. You can either buy these products and services directly from the company's website or use an online travel agent. On the other hand, there are travel review websites where travelers can share their hotel or service experiences.
In essence, our work, will focus more on review websites to tap into the collective intelligence produced by groups of visitors in the islands. The advantage of this process is that it saves time, gives easy access to data, reduces effort to collect data and is relatively accurate.
In its best simplicity, web/data scrapping can be illustrated as follows:
©Clarusway
The Process
This experiment is split into two parts: In the first phase, we will: 1) collect data via web scraping by identifying URLs of targeted sites, 2) prepare a Python environment for scraping, and 3) identify key features to be scrapped. Furthermore, the team will begin data cleaning and transformation, which will include: 1) the removal of non-textual data, language translation, reformatting data time parameters, and visualization of numerical parameters; and finally, the team will begin training and testing the data, which will include sentiment identification for labeling and training data, as well as pre-processing (tokenization, vocabulary building).
The second phase will include several steps, that are: 1) building and configuring a sentiment analysis model, 2) training data, identifying metrics, and evaluating the test data set's mode. In addition, the team will use the model to classify the extracted data into defined sentiments (labels), visualize the prediction results and existing location information and extract key topics.
Web scrapping in process ©Xsense AI and UNDP Tanzania Accelerator Lab
Next Steps
In Tanzania, the use of computer technology, particularly techniques such as web scraping to help inform various socioeconomic challenges in the development sector is still in its early stages of development. However, we are witnessing several tech initiatives in the innovation ecosystem that are utilizing the computer technology and various Fourth Industrial Revolution (4IR) technologies such as AI, virtual reality, mobile apps, and so on to address some of the most complex challenges of our time.
We believe that the findings of this experiment will not only provide a compelling case for the adoption of this technology in tourism programming circles but will also help to inform various development strategies and policies. We anticipate that the results of this experiment will be beneficial to the government of Zanzibar through the Zanzibar Commission for Tourism (ZCT) with key novel feedback data that will support re-branding or marketing of the Islands which will eventually lead to an increased number of returning visitors.
We call for more partners to join us to re-imagine development as we make use of computer programmes to provide solutions to some of the most complex challenges of our time.
Missed our previous blog? Please click here
Special thanks to: Deogtatias Mzurikwao, Director and Researcher at Xsense AI, Tanzania
Written by: Peter Nyanda, Team Lead and Head of Exploration, UNDP Accelerator Lab




