
 Locations
LocationsUso de software libre para analizar datos masivos del Censo 2018 a nivel intra-municipal
30 de Agosto de 2022
Uno de los grandes retos para quienes toman decisiones sobre políticas públicas para el desarrollo es: cómo aprovechar mejor los datos disponibles. Facilitado por la digitalización, los esfuerzos por contar con información cada vez más actualizada, desagregada, precisa y pertinente han resultado en una abundancia de datos. Sin embargo, con frecuencia existen barreras técnicas para utilizarlos.
En este artículo se comparten algunas soluciones para utilizar más ampliamente los resultados desagregados del XII Censo Nacional de Población y VII Censo Nacional de Vivienda realizado por el Instituto Nacional de Estadística en 2018. Algunos de los retos abordados incluyen la capacidad requerida del equipo de cómputo, el acceso y configuración de software, la combinación de bases de datos, la síntesis de información y la generación de resultados.
Los datos a nivel municipal son insuficientes
Para ser efectivas, las políticas públicas requieren adaptarse a las necesidades de sus beneficiarios. Por ejemplo, conocer si hay diferencias en el acceso a un servicio público para distintos grupos permite priorizar la forma en que se ampliará la cobertura de ese servicio.
Sin embargo, cuando los datos se reportan agregados a nivel municipal, no es posible distinguir si el acceso a un servicio es mayor para un grupo que otro. Por ejemplo, tomando un municipio al azar, saber que en Cuyotenango (Suchitepéquez) el 22.3% de las personas se autoidentifican como maya y 26.5% de los hogares tienen acceso a un servicio de recolección de basura no permite determinar si la población maya tiene acceso completo o nulo al servicio de recolección de basura. Por ello, es importante analizar los datos desagregados.
El hardware es caro y el software es gratis pero complicado
Los datos desagregados del Censo 2018 son relativamente masivos. Pueden descargarse aquí. Una vez expandidos, los datos ocupan alrededor de 3.32 Gigabytes. La información se distribuye en distintas bases de datos (personas, hogares, vivienda) que en conjunto incluyen registros de más de 14.9 millones de observaciones y 130 variables. Si bien no se requiere de supercomputadoras trabajando en paralelo para manejar esta cantidad de información, es recomendable contar con una computadora con 16 Gigabytes de memoria RAM.
Una vez se cuenta con el equipo, existen alternativas de software sin costo para el procesamiento y análisis de la información. Una de las herramientas más populares, y que se utiliza a continuación, es la combinación de R y R-Studio. Sin embargo, aprender su uso básico puede requerir entre 10 y 15 horas de instrucción. También, para procesar datos masivos, es necesario configurar un aumento de memoria disponible para el software. Una vez superada la barrera del equipo, se abre la puerta al uso de datos.
Primero, se combinan los datos centrándolos en las personas
Al inspeccionar los datos desagregados del Censo 2018, lo primero que se observa es que no es posible analizar, inmediatamente, las características del hogar o vivienda en que viven las personas. Es decir, se puede reportar los años de escolaridad promedio de las personas ladinas, pero no si tienen acceso al servicio de recolección de basura. Esto es así debido a que, para ahorrar tiempo en la recolección de datos y espacio en el almacenamiento, las características de los hogares y de las viviendas se recoge por separado.
Para combinar la información de las distintas bases de datos, lo recomendable es centrar los datos en las personas. Esto implica que en cada fila de la base de datos, se incluyen las características de una persona censada, y se agregan las características del hogar y vivienda repitiéndola para cada persona que la habita. El código de referencia utilizado para realizar esta combinación de datos está disponible aquí.
Luego, se crean las variables de interés y re-comprimen a nivel municipal
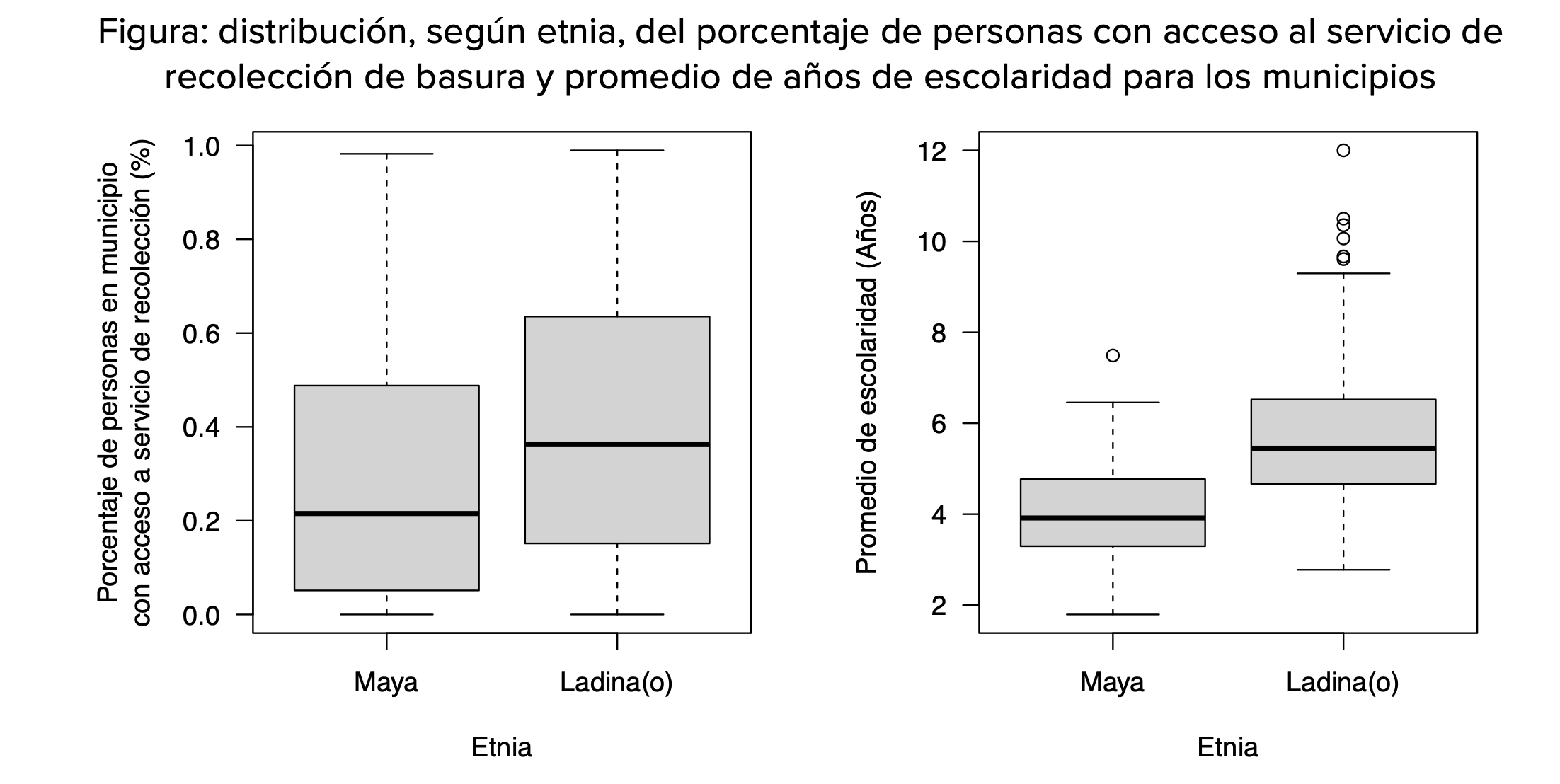
A partir de la base de datos combinados creada en el paso anterior, se hace posible crear variables que permitan un análisis más detallado del municipio. Por ejemplo, combinando características de las personas es posible crear variable a nivel municipal que indiquen aspectos como: (1) cantidad de personas que se autoidentifican como maya o ladina(o); (2) cantidad de personas, según etnicidad, que cuentan con acceso a servicio de recolección de basura; (3) promedio y desviación estándar de los años de escolaridad, según etnicidad.
El código de referencia utilizado para realizar esta creación de variables y re-compresión a nivel municipal está disponible aquí. Es posible adaptarlo para crear otras variables de interés.
Finalmente, se analizan los resultados a nivel intra-municipal
A partir de este proceso, es posible ofrecer mayor luz sobre el acceso al servicio de recolección de basura en Cuyotenango (Suchitepéquez). Ahí, el 22.3% de las personas se autoidentifican como maya; del total de estas, 15.6% tienen acceso a servicio de recolección de basura. Es decir, en el municipio, 3.5% son personas maya con acceso al servicio y 18.9% son personas maya sin acceso al servicio. Por el otro lado, del 77.0% de personas ladina(o), 27.0% tienen acceso al servicio. Es decir, en el municipio, 20.7% son personas ladina(o) con acceso al servicio y 56.2% son personas ladina(o) sin acceso al servicio. Esta diferenciación de las brechas en el acceso al servicio abre la posibilidad de implementar acciones focalizadas a los distintos grupos en distinta medida.
De forma similar es posible indagar si existen diferencias entre el promedio de años de escolaridad entre personas maya o ladino(a) en Cuyotenango (Suchitepéquez). En promedio, las personas en el municipio tienen 5.3 años de escolaridad. En más detalle, se observa que las personas maya tienen un promedio de 4.2 años de escolaridad y las ladina(o) 5.6. El código utilizado puede consultarse aquí, y las siguientes gráficas muestran la distribución, según etnia, de los porcentajes de acceso al servicio de recolección y el promedio de años de escolaridad en los municipios.
El procedimiento compartido en este artículo muestra que es posible utilizar software libre para analizar los datos masivos del Censo 2018 a nivel intra-municipal. Su uso permite dilucidar diferencias entre las características de distintos grupos imposibles de observar a nivel agregado. Utilizados con prudencia, y conscientes de sus limitaciones, los datos reducen incertidumbre y ofrecen un punto de referencia común a quienes toman decisiones sobre política pública para el desarrollo.
