
 Locations
LocationsAn experiment in collective intelligence to assimilate the lessons learned by the people who operate budgetary programs and who are at the forefront of the implementation of public programs.
A lab experiment that can help identify and address potential gaps in public speding performance
29 de Diciembre de 2021


Photo by Michael Dziedzic on Unsplash
In the previous blog we laid the groundwork for a text mining experiment we conducted at the PNUD Acceleration Lab in Mexico to collectively assimilate the main lessons learned by people on the front lines of public program implementation. In this post we share with you the main results and recommendations for the architecture of the Performance Assessment System as a collective intelligence to help enhance the continuous improvement of public programs.
The similarity algorithm
The goal of the experiment was to find a way to make sense, in aggregate form, of the thousands of text records entered by individuals into the Performance Assessment System. In them, people explain the reasons that in their opinion best explain why they did not reach a certain goal to which they had committed themselves. The similarity algorithm we developed evaluates text matches with the predefined causes contained in the GUIA that the Ministry of Finance and Public Credit sends each year to the agencies, and does so independently. In other words, the same text may be similar to several of the causes. Which tells us that the person is possibly talking about a mixture of several of these causes.
The algorithm is not perfect, but it has the ability to learn. A series of tests were carried out to validate that the similarity measure provided by the algorithm does indeed relate what the texts say to the predefined causes. Then a threshold was defined, from which it was considered that the similarity with each of the causes was sufficiently high, and that therefore, there is a high probability that the person who wrote it is referring to it.
From the total database, the algorithm was able to estimate an independent similarity measure for each of the nine causes in 41,509 indicators (many do not contain justification text). Of these records, 9,830 correspond to indicators that did not reach their goal during this period and are the universe of analysis of this experiment.
What do people talk about?
The graph below shows the aggregated results to answer the question: What causes are people talking about when they write their justification texts on the non-compliance with budget program goals? The first conclusion is that on average, several causes are blamed at once. On average, we found that the justification texts coincide with 2.58 causes.
Each line is one of the nine previously defined causes. The one at the top is the most commonly mentioned in the database, this vertical position allows us to see which ones are mentioned most frequently. This is an inter-causal analysis. Following the same line over time shows us the trend over time in the frequency with which each of the causes are mentioned.
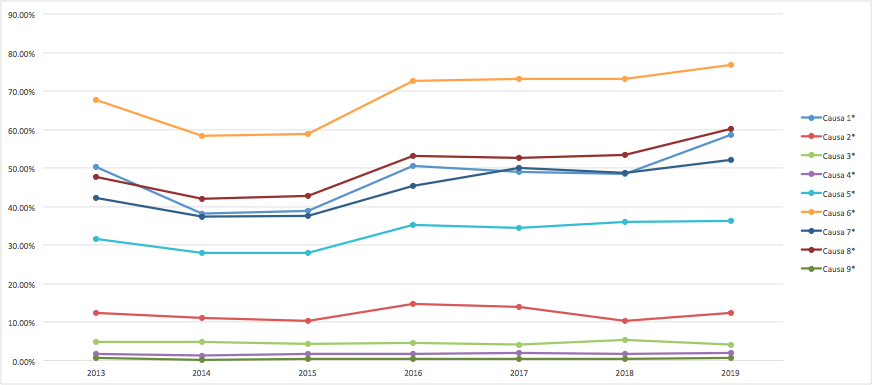
Source: Own elaboration based on information provided by the PbR - PASH UED.
The most common cause is cause 6: "Non-compliance or non-conformities of suppliers and contractors, as well as opposition from social groups", present in more than 70% of the justifications. It is followed by cause 1 "Deficient original programming", cause 8 "Non-compliance or delay in the procedures for the budgetary exercise by government agencies other than the RU", cause 7 "Modification of institutional attributions due to regulatory provisions" and cause 8 "Non-compliance due to extra-budgetary regulatory situations outside the RU of the goal".
How to use this information to promote continuous improvement?
If you were a person in a decision-making position at the highest level, this is information you need to know in order to take action. But not only that, it is also extremely important information for the general public, academics, advocacy groups and anyone interested in improving the performance of public policies. Now, let's suppose that in addition to this, we are interested in knowing the situation in a specific area of expenditure or for a specific program modality.
With the information we have available in the database, the same graph can be replicated within each industry. The example below only refers to branch 15: Agrarian, Territorial and Urban Development. We see that the conclusions change slightly. Non-compliance or non-conformities of suppliers and contractors, as well as opposition from social groups, continues to be the most mentioned cause, but now the trends over time and the years in which the mention of the causes reaches its peak. This information helps us to know where we should focus our attention if we wish to improve our public policies by attacking the causes.
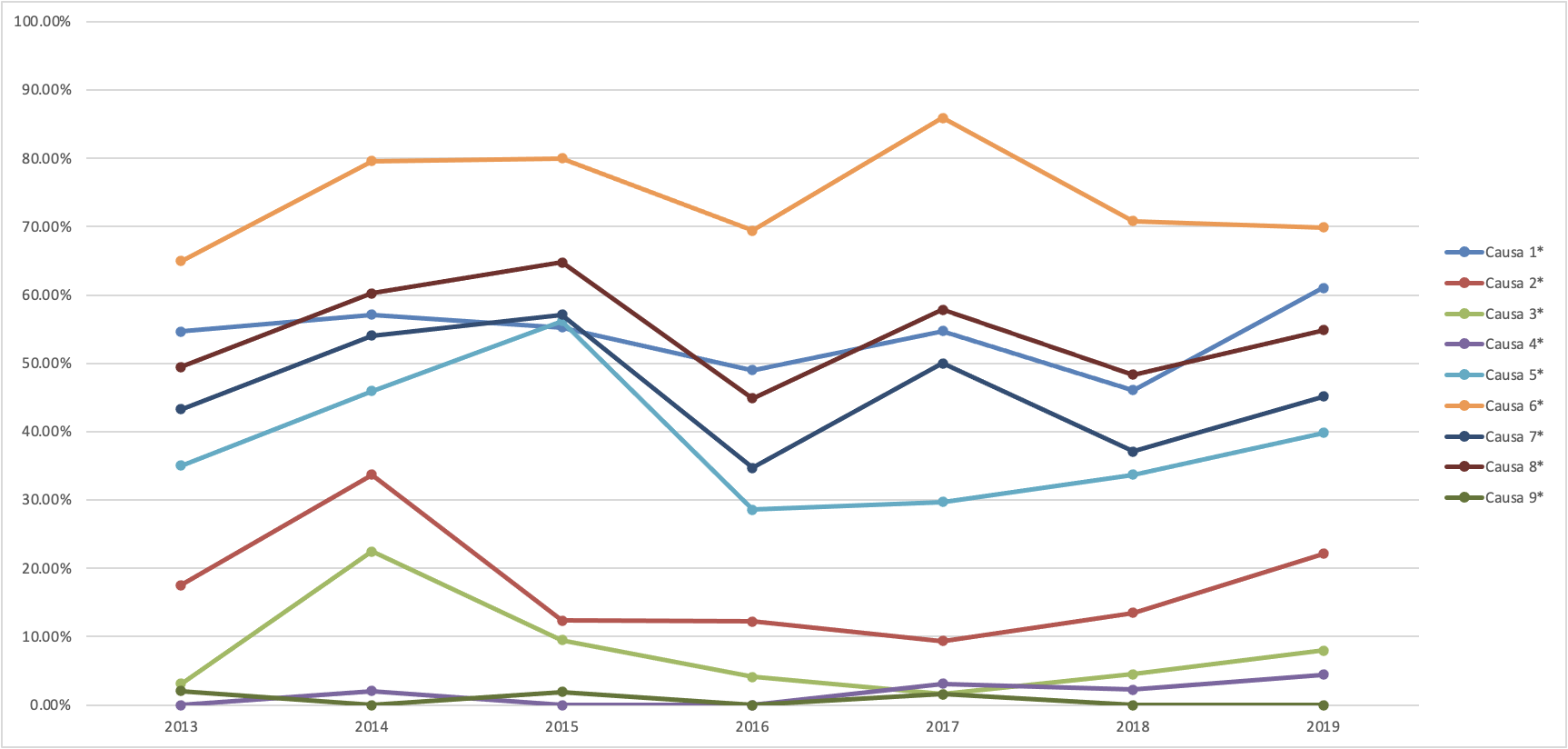
Source: Own elaboration based on information provided by the PbR - PASH UED.
But the analysis does not stop there. Another way to view this same information is through ordered lists or rankings. The exercise shown below can be performed for each of the causes, but for this example let's take only cause 8: "Non-compliance due to extra-budgetary regulatory situations outside the UR of the goal." We can create a list to help us answer the question: In which area of expenditure is this cause most frequently mentioned?
The following graph shows all the branches ordered according to the relative frequency with which this is mentioned as the reason why the programs do not reach their goals. Three areas of spending stand out: Labor and Social Welfare, Attorney General's Office and Culture. The data produced by our exercise have the potential to become indicators of performance assessment at the aggregate level and this type of listing is a source of incentives to promote continuous improvement and direct attention to the causes that explain what people mention most frequently.
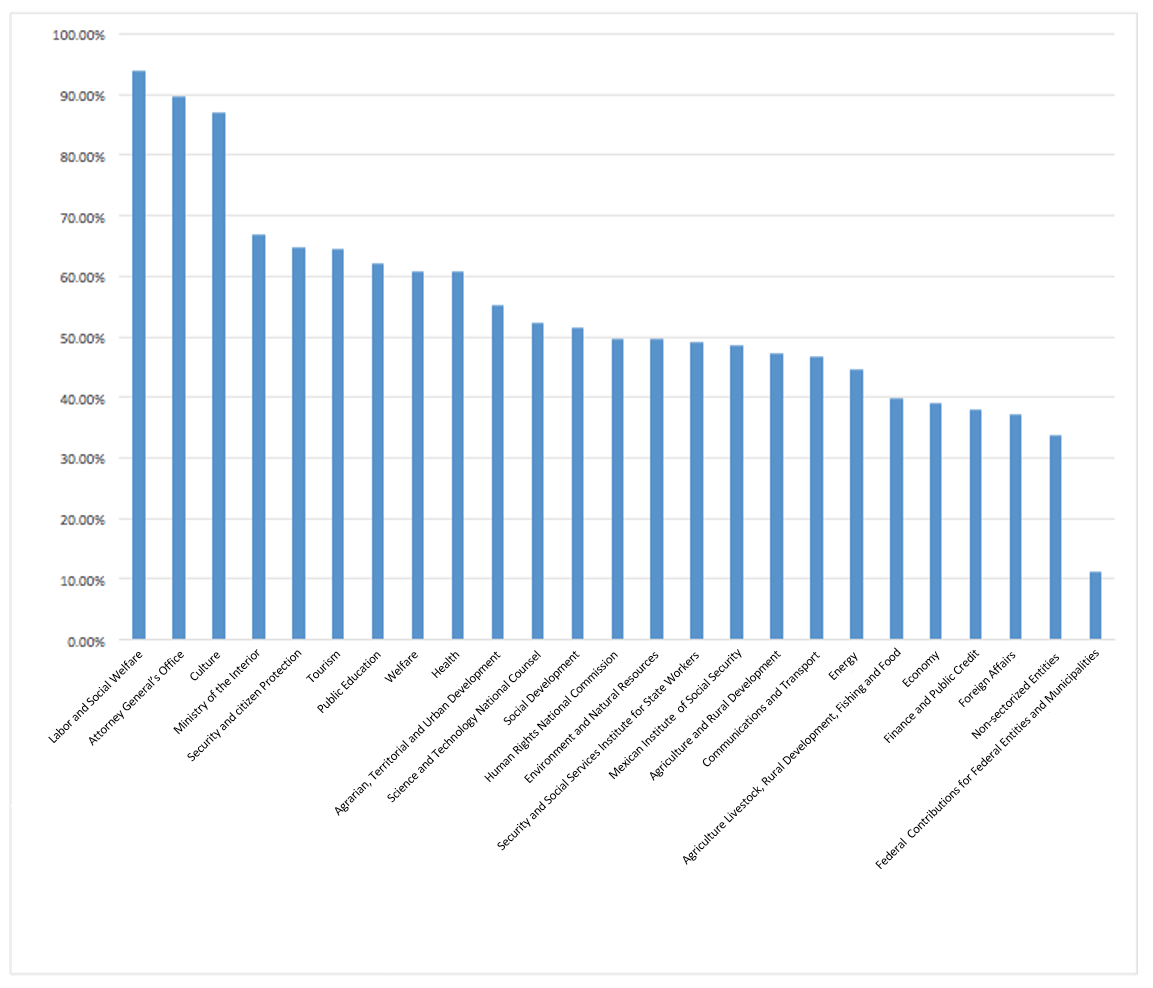
Source: Own elaboration based on information provided by the PbR - PASH UED.
Finally, we should not forget that budgetary programs differ according to their modality and that the causes that explain the performance of the indicators may vary among different types of programs. Another way to exploit this data is to create ordered lists or rankings by modality.
Taking as an example again cause 8: "Non-compliance due to extra-budgetary regulatory situations unrelated to the RU of the goal", the following graph shows in which expenditure modalities it is most commonly mentioned. In this case, in the "R: Specific" programs, this cause is mentioned in more than 60 percent of the cases. On the other side of the spectrum, only 10 percent of those in modality "I: Federalized spending" are mentioned.
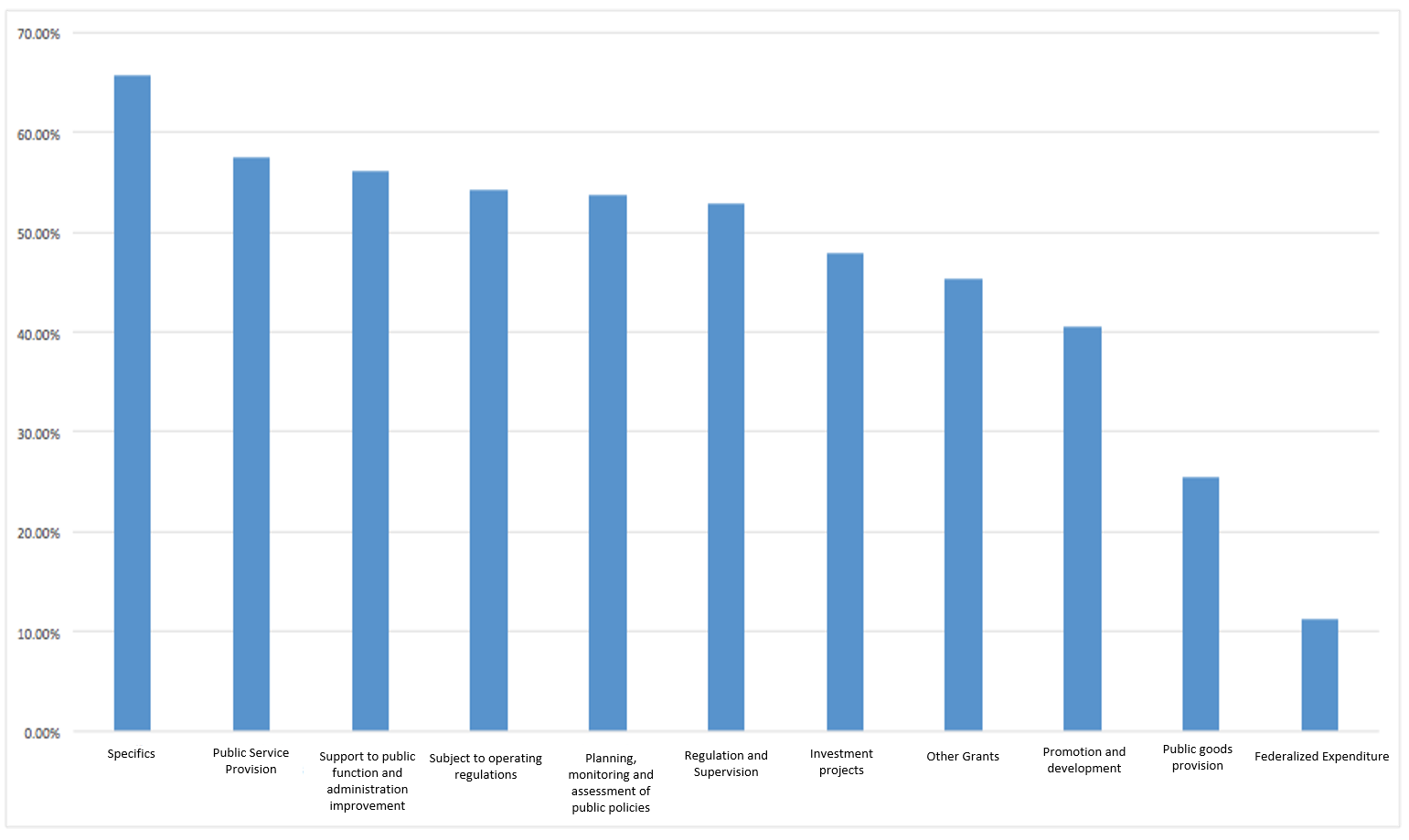
Source: Own elaboration based on information provided by the PbR - PASH UED.
Finally, thanks to the algorithms developed by the UNDP Acceleration Lab, information that is originally qualitative in nature and contained in the Performance Assessment System's indicator progress databases can be converted into general interest data and intelligence on the performance of public policies.
We will soon publish a specific report with all the methodological details of this exercise. Wait for it! In the next blog, we will tell you how the principles of collective intelligence operate and how this exercise has the potential to be refined over time and become an inexhaustible source of learning for continuous improvement.
Do you have experience in data science and text mining, are you familiar with the Mexican Government's Performance Assessment System, or would you like to share with us ideas on how technology can be incorporated into the design of improvements in the Results Based Budgeting? Write us, we want to hear from you!
Related Content




