Deforestation, Cows, and Data: Data Powered Positive Deviance Pilot in Ecuador’s Amazon
Deforestation, Cows, and Data: Data Powered Positive Deviance Pilot in Ecuador’s Amazon
June 10, 2021
Author: Ana M. Grijalva, Head of Exploration, UNDP Accelerator Lab Ecuador, Paulina Jiménez, Head of Solution Mapping, UNDP Accelerator Lab Ecuador with Basma Albanna, Doctoral Researcher, University of Manchester, and Jeremy Boy, Network Data Visualization Engineer, UNDP Accelerator Labs.
No Forest, No Life: The Importance of Deforestation
Deforestation is an alarming problem for the Amazon region. In Ecuador alone, the rainforest recedes by hundreds of hectares every year. This is almost exclusively due to agricultural activities — 99% overall, and 64% due specifically to pastureland (PROAmazonia, 2019). Put simply, much of the land originally covered by forest is now being transformed into pastureland. In fact, the rate of deforestation at the farm level in certain counties has grown tenfold between 2019 and 2020, from 1.3% to 13% (DPPD Ecuador initiative, 2020); and the deterioration of socio-economic conditions due to measures taken in response to the Covid pandemic is putting even more pressure on this precious natural resource.
We, at the UNDP Ecuador Accelerator Lab, GIZ Ecuador, the GIZ Data Lab, and the University of Manchester, are using a combination of various readily available data types from different sources, and a methodology named Data Powered Positive Deviance to identify local, sustainable cattle farming practices that have a low deforestation imprint. Our work supports PROAmazonia, an ambitious five-year programme run by a coalition of stakeholders — including UNDP, the Ecuadorian Ministry of Environment, and the Ministry of Agriculture — that aims to reduce CO2 emissions by mitigating deforestation and promoting sustainable land use.
Rule by the Exception: Utility of a Mixed-method Approach Focusing on Outliers
Data Powered Positive Deviance is a twofold method for learning about local, effective and desirable practices developed by a subset of individuals within their communities, in response to the problems they collectively face. The method starts with a quantitative analysis phase, followed by a qualitative inquiry phase. The quantitative phase aims to identify potential positive deviants using a combination of readily available data to limit the scope of necessary fieldwork in the qualitative phase. The latter phase then aims to validate the deviances identified in data, and to understand more precisely what sets positive deviants apart. This post focuses mainly on our work in the quantitative phase.
We seek positively deviant cattle farming practices that have a low deforestation imprint in Joya de los Sachas and Sucúa, two counties in the Amazon region of Ecuador, over a five-year period, from 2015 to 2020. We define positive deviants as farms (and the farmers who own or work on them) that maintain a small annual deforestation rate — under 1.3%, as defined by the Ministry of Environment — that further falls below what might be locally expected, given a number of structural and contextual constraints. We build statistical models to derive these expected rates of deforestation for groups of farms, accounting for, e.g., general practices in the area in which the land is, the quality of the soil, and the amount of cattle on the parcel. We then compare expected rates of deforestation with those observed on each farm: if the observed rates are consistently lower than the expected rates for the last three consecutive years (2018–2020), and if these rates fall below the 1.3% threshold, then farms are considered potential positive deviants.
The challenge with this statistical modeling approach is that it is extremely difficult, if not impossible, to account for all the variables that might link cattle farming to deforestation. Based on conversations with public officials from the Ministries of Environment and Agriculture, and with colleagues from the UN Food and Agriculture Organization (FAO), we see two broad sets of issues.
First, cattle farming practices are driven by both intrinsic and extrinsic fators. Intrinsic fators include e.g., a farmer’s household structure, which can influence cattle raising cycles, as a need for cash can push to sell livestock quickly. Extrinsic factors include e.g., the illegal traffic of meat between the Northern border of Ecuador and the Southern border of Colombia, which brings down prices, disincentivizing farmers to pursue cattle raising activities. Collecting data on such factors can be extremely sensitive, and deriving the information from secondary data is generally difficult to validate.
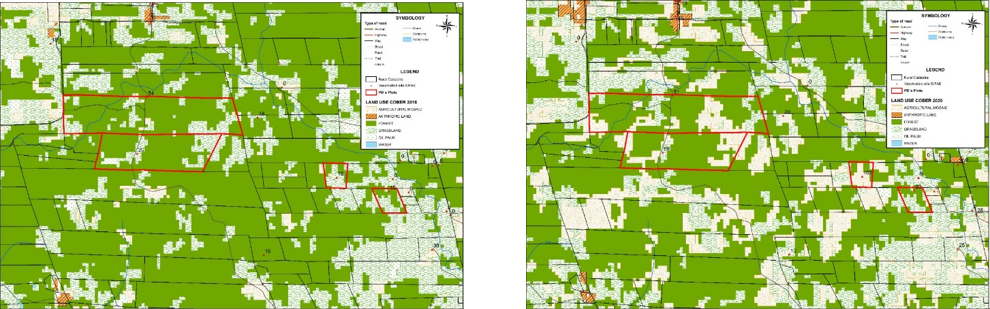
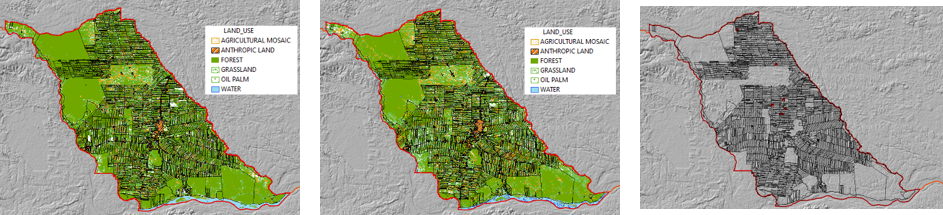
Second, cattle raising is seldom an independent activity on a farm. The same land can be used for pasture, growing crops, cultivating palm oil, or left alone for the soil to rest. This information can be captured by land cover/ land use maps, but these are not always available or frequently updated for our specific counties and timeframe of interest.
To account for these complex dynamics and to further refine our identification of potential positive deviants, we rely on a theoretical conceptualization of statistical residuals. Residuals are essentially the difference between what is expected by a statistical model and what is observed; they indicate how much the model accounts for variations in the observations. We consider the residuals of our models as an aggregate proxy for all the variables we cannot account for, and thus we assume they capture, among other things, the specific positively deviant practices we seek.
Positive Deviants: A Powerful Identification Mechanism
By design, our statistical models control for the following variables:
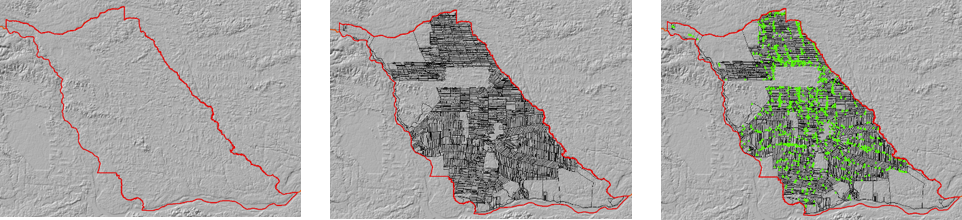
Initial endowment: size of the farm and quality of the soil;
Land use: amount of cattle, number of hectares of crops, palm oil, and resting soil;
Location: proximity to urban centers, proximity to healthcare centers, and access to roads and agricultural facilities;
Socio-economic context: population density and poverty level.
We use traditional data sources like cadastral information and public cattle vaccination registers to respectively identify farm boundaries and amount of cattle. We also use national statistics data and a poverty index to assess the socio-economic status of parishes within our counties of interest. We then combine these data with others from less traditional sources, like remote sensing data to estimate population density at the parish level, to learn about local soil properties, and to calculate the distance between individual farms and their nearest urban infrastructure (e.g. roads, markets, schools, among others). We further leverage machine learning techniques to fill in the gaps of land cover/ land use maps for our five years of interest (2015–2020). We use these maps to measure the number of hectares allocated to cultivating palm oil, crops, pasture, and the area of remaining forest on each parcel.
We then derive a binary performance measure from our models to identify ‘top performers’ who have a small yearly deforestation imprint. For each year between 2015 and 2020, we look at the distribution of residuals for every farm and retain those in the top tenth percentile. These are the top performers for the given year. If a farm consistently remains a top performer between 2018 and 2020 — the last three consecutive years — we then determine it a potential positive deviant at the end of the quantitative phase.
The power of this approach is that it reveals deviance over time. A farm may be a top performer one year, but change its practices the next and start deforesting heavily, turning it into a ‘negative deviant’. The opposite may of course also happen.
In the end, we identify 40 potential positive deviants in Joya de los Sachas among 5332 farms inspected (0.7%), and 13 in Sucúa among 5701 farms inspected (0.2%). This significantly narrows down the amount of fieldwork required to precisely understand positively deviant practices in the qualitative phase.
Superhero Weaknesses: Reflections on Data Power and Limitations
The quantitative phase of the Data Powerd Positive Deviance method relies on a very hands-on data innovation approach. Our work highlights some of the potential, and several limitations of using exisiting data to understand highly situated dynamics, and the feasibility and applicability of combining multiple secondary data sources of various types.
Each data source we use has its own scope of relevance, based on e.g., the way they were collected, the methodological assumptions that were applied when processing them, or the level of aggregation at which they are made available. By using these readily available sources, we reduce the cost and time of data collection, but we expose ourselves to imperfect answers to our research questions. For example, only having access to socio-economic data at the parish level, and not at the farm level, only allows for approximate alignment with other variables. Deriving aspects of cattle efficiency is also challenging, when information on e.g., cattle weight or breeding time is not available for each farm. As a workaround, we use a proxy measure of amount of cattle per hectare of pastureland, which is not optimal and requires proper validation.
We also realize that positive deviance at this stage is a relative concept: positive deviants are only outliers in statistical terms, relative to the distribution of an abstract measure (the residuals of our models). Presuming our theoretical conceptualization is correct, this only implies positive deviants are ‘better performers’ than their immediate peers. It is possible, in a bigger picture, that their practices are ultimately not so desirable.
Guided by the results of the quantitative phase, we next conduct in situ interviews to better understand the uncommon practices of our potential positive deviants. The first step in this direction consists in discussing data validation, understanding positive deviant categories descriptively, and shifting from quantitative results to a narrative that enables the design of a qualitative inquir
We begin with an exhaustive key informant mapping at the national, province, and local levels, and participatory design sessions with local technicians who are able to provide a general profile of each farmer, as well as preliminary information of their characteristics. This ensures diversity, and the exclusion of intermediary farmers. The result is a selection of 19 farmers to interview.
To access the farms, it is key to have an ethical protocol, and local technicians have a gatekeeper role. Socialization meetings with farmers are crucial to express the objective of the study, reduce resistance, and clear away suspicions of political interests — especially since our fieldwork happens to coincide with elections. Finally, regarding the environment, deforestation is a sensitive topic, and it is crucial to be able to win people’s trust to obtain the necessary information.
We are currently processing the qualitative data we collected. Stay tuned for our final results!
With special thanks to Basma Albanna, Andreas Gluecker, and Jeremy Boy for their insightful comments and a special appreciation for all the hard work of Santiago Sghirla, Jhonny Rodriguez, and Diego Villacreces.
About
The Data Powered Positive Deviance initiative was established on the belief that lessons on how to tackle complex sustainable development challenges are best learned from the people who face those challenges every day. It is with this mindset that the GIZ Data Lab, the University of Manchester Centre for Digital Development, and the United Nations Development Programme Accelerator Labs are conducting a series of pilots in different countries and domains to uncover effective, locally developed practices and innovations as a response to development challenges.

 Locations
Locations